Technical SEO: Tools and Approach
Where do you start? What types of areas should you be investigating, and why? What factors really matter? What tools should you use? Your questions answered here.
Where do you start? What types of areas should you be investigating, and why? What factors really matter? What tools should you use? Your questions answered here.
While search engine optimization (SEO) as a channel is maturing and growing beyond technical competence only, there will always be a great deal of technical attention necessary in the work.
Some of the biggest problems negatively impacting SEO campaigns can be traced back to technical issues, since by nature they tend to hit areas around crawling, accessibility, redirects, and indexation. These are core, foundational areas that every hard working organic search marketer needs to be familiar with.
Having seen the results of technical work, I can attest first-hand that some of the best SEOs in the world are highly technical people. They have that unique combination of technical acumen and marketing savvy, a rare thing to find.
Most professionals realize that attention to the technical side is important in SEO. But where do you start?
What types of areas should you be investigating, and why? What factors really matter? What tools should you use?
I recently presented on this topic at SES New York alongside Brian Ussery, Brett Tabke, and Jaimie Sirovich, so this is especially timely for me.
What Technical SEO Factors Matter?
With so many potential variables at stake, where does one begin in technical SEO? And additionally, what factors matter the most? In our experience, technical work can be focused primarily on the crawling and indexation aspects of SEO.
Conceptually, SEO work can really be boiled down to three primary “chunks”: crawling, indexation, and ranking.

While there can be technical issues at all three levels, our primary concern is with crawling first, and indexation secondly. However, indexation is really secondary to crawling: without a site that is accessible and easily crawled, nothing will be available for indexation. For this reason, we focus first on crawling and accessibility.
The crawl experience is a first-order effect, and everything in SEO comes after that experience. (In reality, the crawl > index > rank concept is quite circular, because each component influences the other, but for the purposes of this discussion we’ll treat them as separate and distinct.)
I’ve given AudetteMedia’s list of SEO factors before in my article on SEO audits. It’s helpful to provide that here again, in order to demonstrate the sheer magnitude of potential issues. There is a lot of stuff to think about!

The key, however, is that while lists of potential factors like the above can be helpful guidelines, there is no recipe for technical SEO analysis. It’s always different, based on the site at hand, the problems being worked on, and the technology in question.
Therefore, instead of thinking of every possible component that could be a factor, think of these high-level factors as the most pressing and highest impact with regards to technical SEO:
While there are many other areas to investigate, the above eight points represent key areas that are fundamental to a site’s technical SEO.
Tools for Technical Analysis
The cornerstone of solid technical SEO work is experience with solid toolsets. This is where you’ll find a multitude of resources and options, because every practitioner will have her favorite tools for the job. Here are mine, and I’d love to hear from others in the comments with other recommendations.
Remember that technical SEO work is really about correctly diagnosing (sometimes complicated) web requests, masking as another user agent such as Googlebot or Safari, or as a user in another country such as Italy or South America. For that reason, I always prefer to use the hardcore tool: the command line shell.
Most SEOs wince at the thought of firing up the command line, but remember that when working on technical projects, it’s all about time and efficiency. Because of the nature of the work, hours (even days) can be spent looking at specific things and working over data, only to find that the real issue at hand wasn’t actually related. When you have the ability to quickly open the shell and fire a couple of commands before looking deeper, it can save a lot of time.
Two of the most often used commands for fetching a URLs response headers are wget and curl. Both are quite powerful and very fast. Here’s an example of issuing the command on a site:
% wget -R –spider www.mydomain.com
This command tells wget to fetch the response headers and mask as a spider (thereby saving the time and space to fetch the entire file and save it locally). Without the spider argument, you’ll have a lot of locally saved files for pages for which you’re just concerned with checking the response headers.
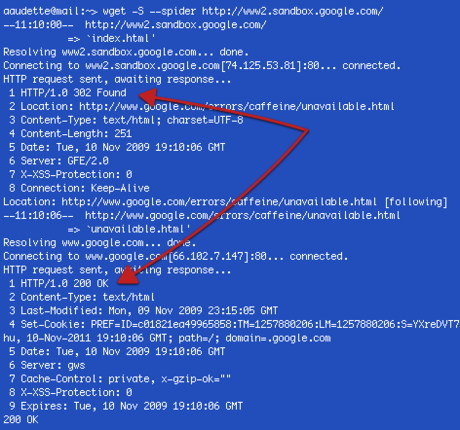
wget is a powerful tool for checking things like multiple, chained redirects.
When you need to check a single URLs status code response and don’t care about following redirects, curl is a fabulous and elegant solution. The following syntax will return status code for a URL (please note the argument given is an upper case ‘ i ‘ not a lower case ‘ l ‘):
% curl -I www.mydomain.com
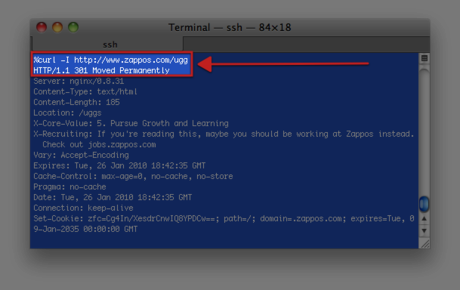
Curl, too, can mask as another user agent such as Googlebot:
% curl -I -A googlebot www.mydomain.com
This is a great way to find conditional redirects, such as the one demonstrated here (user agents visiting this site without the ability to accept cookies get 302 redirected):

When problems are sniffed out and investigated with the command line, it is then most efficient to use a graphical application for deeper analysis. My preferred choice for deeper technical work is Charles, a web proxy tool that serves as “man in the middle” between a web server and your browser. Charles captures everything happening between the server and the client, and records it in organized fashion.
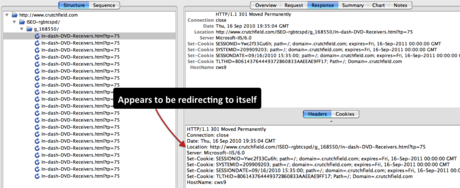
When you need to examine chained redirects to drill into the responses, this is a great tool to use. It’s also quite useful when looking for things like conditional redirects (when a different response is given based on the user agent).
Such an example is demonstrated below. While browsing this site as Googlebot and then again as Firefox (using the User Agent Switcher in Firefox), different responses are recorded. Below is the response for Googlebot:
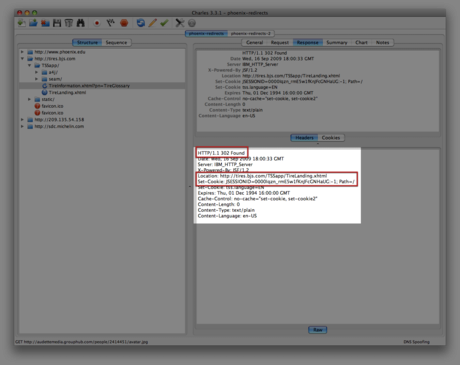
This is the type of technical SEO investigation that can have a big impact on a site. In the above example, the entire subdomain is unable to be crawled and indexed if cookies aren’t enabled (search engine bots don’t accept cookies).
Because of this implementation, the subdomain is basically invisible in organic search, although there are quality pages on the site. Ouch!
SEO Crawlers
An article could easily be dedicated to just the topic of SEO crawler tools. I’ll be brief and just mention a few here that can be useful tools.
Log File Analysis
Log file analysis is a critical component of technical SEO. However, deep analysis is often difficult because of the size of the data (log files for big sites are ridiculously huge) and the problem of parsing out just what you need.
That’s why we developed a command line tool for this job called logfilt. It’s a SEO log analysis tool and is free to download.
Logfilt is written in sed and nawk (there is an awk version, too) and is tremendously fast. It is designed to be efficient and minimalist. You can parse through large data sets easily — the only thing holding you back will be your machine’s memory (for big data sets, run this tool on a big box).
One of the benefits of doing log analysis from the command line, is that you can put together very complex searches using regular expression. Graphical log diagnostic tools such as Splunk and Sawmill are also highly recommended, and can do the same types of searches (with custom configuration). However, if you have technical chops and aren’t afraid of the command line, doing the work there can save time.
Please see my site for a complete description on using logfilt, but briefly, here is an example of the syntax you would use to find all 302s reported by Bingbot in a specified period of time, and save them to a file:
% logfilt -H bingbot -R 302 big_log_file > 302.txt
To return all URLs crawled by a user agent (Googlebot in this case) over a specified time period, issue:
% logfilt -H googlebot log-Apr-1 log-Apr-2 log-Apr-3 | less
(You’ll note the above example is piped to the command less, which is handy for pagination in the shell. You could just as easily save the output to a file.)
One of the cool features of the second example above is the output. The crawl is given chronologically, showing the exact crawl path of the user agent by individual URL. This can be a powerful set of data to examine.
Below is an example of the same command syntax, using Yahoo Slurp (now deprecated in the U.S., but still actively crawling internationally).

Bonus Tip: Crawl Your Top Pages
There is much more to write, but in the interest of time and space we’ll save that for another installment. Stay tuned for a future article where I’ll discuss log file analysis for SEO purposes.
Before departing, however, I wanted to leave you with one easy win.

Leave a Reply
You must be logged in to post a comment.