Does your website suffer from one of these five content gaps?
In 2016, Google rolled Panda into its core algorithm. What this means for webmasters is that a website can be hit by (and recover from) a content penalty at any time.
But, more problematically, it also means it’s becoming impossible to diagnose why a website has dropped in rankings. Google ultimately does not want us to understand how its ranking algorithm works, because there will always be people who manipulate it. We now suspect that core signals are rolled out so slowly that SEOs won’t even realise when Penguin or Panda has refreshed.
For this reason, it makes it crucial that we understand how well our website is performing at all times. This blog post is intended to show you how to do a comprehensive content audit at scale, in order to find any gaps which may lead to rankings penalties.
Essentially, there are five types of content gaps a website may suffer from. I’ll explain each one, and show you how you can find every instance of it occurring on your website FAST.
Internally duplicated content is the daddy of content gaps. Duplicating optimised content across multiple pages will cause cannibalisation issues, wherein Google will not know which internal page to rank for the term. The pages will compete for ranking signals with each other, reducing the rankings as a result.
Further to this, if you have enough duplicate content within a directory on your site, Google will treat that entire directory as low quality and penalise the rankings. Should the content be hosted on the root, your site’s entire rankings are under threat.
To find these at scale you have to use Screaming Frog’s custom extraction configuration to pull all your content from your site, then compare in Excel for duplicates. Using this method, I was able to find 6,000 duplicate pages on a site within a few hours.
To configure Screaming Frog you first need to copy the CSS selector for your content blocks on all your pages. This should be relatively simple should your pages follow a consistent template.
Go onto the page, right click on the content and go to inspect element. This will open up the right panel at the exact attribute which you right clicked on. From there, right click again, but on the attribute, go to copy, then select copy selector:
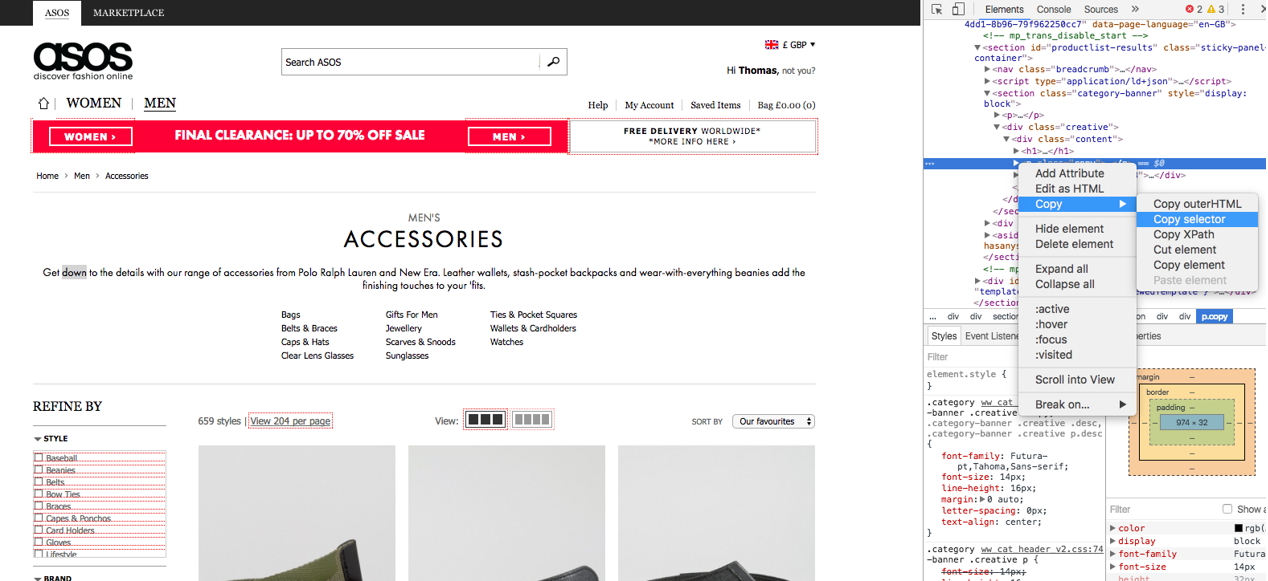
From here you need to go into Screaming Frog. Go into the configuration drop down and select custom, then extraction.
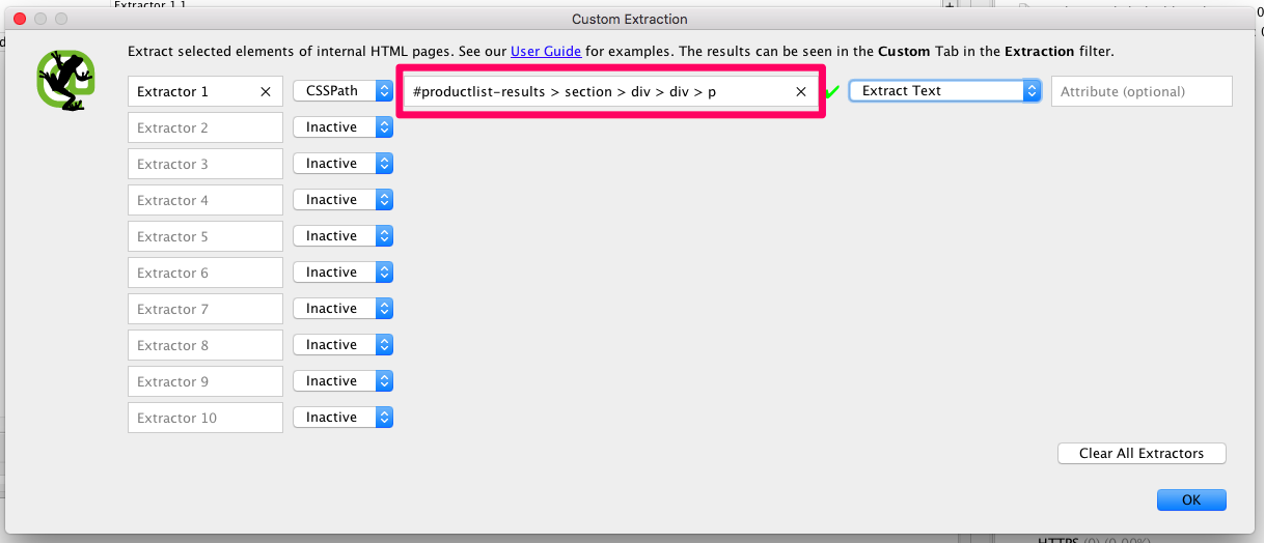
From here this will bring up the below box, which you will then need to select CSSPath as the mode, and then paste your selector into the highlighted field, and change the second drop down to extract text.
Now if I run a crawl on the ASOS website, Screaming Frog is going to extract the above the fold content from all the category pages.
You can specify up to 10 separate paths to extract, so when you have templates with multiple content blocks, for example above and below the products, or category and product & static page templates, you will need to specify them in the same way I have just shown.
Now, it is going to be very unlikely that an entire page’s content, or an entire block of content, will be duplicated. Usually spun content keeps the majority of the content the same but will replace specific keywords. So trying to find duplicate content based on entire blocks of content is pretty futile. Luckily I have created a duplicate content tool for this exact situation.
Fire up the tool and input just the URL and content into the specified columns on the input tab. Essentially what we have to do is split the content down into sentences and compare occurrences this way.
The output will only work if you have a single content column, so if you have had to extract multiple content blocks on each URL simply combine them before you paste into the tool. You can do this with the concatenate function which for example would look like this (should your content be in columns A2 & B2).
=concatenate(A2, “.”, “B2”)
The period in the middle is essential (if your content does not contain periods at the end) because we are going to split the content out by text to columns by full sentences, so will use the period as the delimiter.
Next highlight the column with the content in it, then select text to columns. Select delimited, then select other and specify a period as the delimiter.

Once you have done this you will need to amend the formula in column A3 depending on how many columns of delimited text you have.

In my example I have ten columns so I will edit the formula to display as this:
=A2+10
Drag the formula down so we’re adding ten onto the figure of the preceding cell. This step is necessary as it allows us to group our delimited content by URL on the Output sheet.
From here your Output sheet will auto populate. If you’ve got over 100,000 rows of data, you will need to drag the formulas down until you get errors.
From here I would lock down the formulas by pasting as special to speed up the spreadsheet. Then clear up the Output sheet by removing all errors and 0s.
Finally go into the pivot table spreadsheet and refresh the table to show all URLs sorted by highest amount of duplicate occurrences. You can expand the URL to see exactly which sentences are being duplicated.

In this example I found a ton of pages (6,927 pages) which had heavily duplicated each other within a couple of hours total.
Externally duplicated content is content which has either been purposefully syndicated on multiple websites, or scraped by malicious web robots. A prime example of externally duplicated content is companies copying manufacturers descriptions instead of writing something unique.
When a search engine discovers content which has been duplicated across multiple websites, it will often work out the originator of the content and then throw the rest out of its index. Normally it is pretty good at this, but if our website has issues will crawl budget, or gets its content syndicated by a website with far greater authority, there is a chance that Google will show them over us.
Finding externally duplicated content begins much in the same was as before. Extract your content from the website and use the download to split the data out into individual sentences.
Next, we just need to block quote some of the data and search it into Google (use concatenate to quickly put all your data into block quotes). To automate this process, we have our own tool which can do this for thousands of searches at a time. A good free alternative would be to use URL profiler’s simple SERP scraper.
What you’re essentially doing here is performing a search for a block of your content in Google. If your site doesn’t show up in P.1 for this, then you have a big problem.
Search Engine Watch is heavily scraped. Here I have done a search for a bit of a previous blog post of mine, and Google have found 272 results!

Search Engine Watch is still in first position, which is not an issue, but should you find instances where you are outranked, you’re going to have to rewrite that content.
The impending mobile first algorithm means this issue should be at the forefront of everyone’s minds. Google have publicly stated that desktop websites will be judged on the content which is displayed on their mobile site first. This means if we have mobile pages without content where it appears on desktop, we’re going to take a hit to our rankings.
To find content gaps it’s the same process as before. You should already have crawled all of your pages from a desktop point of view. Now you just need to go through all the templates again, but in mobile view.
Fire up the webpage and go into inspect element and change device to mobile:
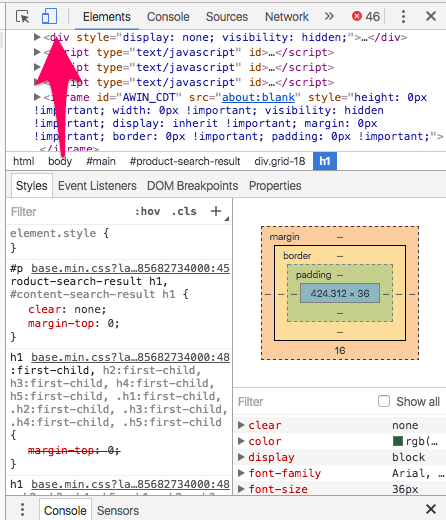
Go into the body of content and copy the selectors in the same way as before and run a crawl on all your URLs again.
Once you are done you can compare content side by side in Excel for gaps. Remember to concatenate your data should you have multiple selectors per page.
Put them in an Excel doc and a simple function will help you spot gaps instantly.

Here all I did was the following function and I’ve got some results instantly:
=IF(B2=C2, “Match”, “No Match”)
The consensus now seems to be that accordions are okay on mobile, so don’t worry about compromising your design to get all your content in. Just make sure it is all there on the page.
Thin content is just as big a concern as duplicate content for the obvious reasons. Without a significant amount of valuable content on a page Google will not be able to understand the topic of the page and so the page will struggle to rank for anything at all. Furthermore, how can a webpage claim to be an authority on a topic if it does not contain any information on it? Google needs content in order to rank a page, this is SEO 101!
Luckily, we are already 90% of the way there to diagnosing all our thin content pages already. If you have completed steps 1-3 you’ll already have the content on your mobile and desktop website by URL.
Now we just need to copy in this formula, changing the cell reference depending on what we’re analysing:
=IF(LEN(TRIM(B2))=0,0,LEN(TRIM(B2))-LEN(SUBSTITUTE(B2,” “,””))+1)
This will give us the word count of the URL (for both mobile and desktop). Then go through and raise any pages with less than 300 words as requiring additional content.
The final type of content gap is a massive bugbear of mine. It is estimated that 80% of our attention is captured by the section of a webpage that is visible on page load.
Google understands that content buried at the bottom of a page is probably never going to get read. As a result, they do not give as much weighting to the content here. No matter how much valuable content you have on a page, if a significant chunk of this is not visible on page load then this is a wasted effort.
In order to diagnose how much above the fold content we have, we will need to rerun our crawls, but this time we only want to extract the content blocks which are visible on page load. From here, just running the above word count formula will be sufficient to diagnose content gaps.
There you have it. What do you do with duplicate/thin content pages once you discover them? I’d recommend every URL should have at least 200-300 words of unique, valuable content on it, with at least 50-100 words appearing above the fold. If you cannot produce that amount of valuable information on the page, then either the page should not exist or the page should not be indexable.
Leave a Reply
You must be logged in to post a comment.