SEO can be boiled down to three core elements, or functions, in the current era of Google: crawling time (discovery), indexation time (which also includes filtering), and ranking time (algorithmic).
Distilling SEO to these core factors allows SEOs to construct a framework for their work around the activities the engines are conducting, without having to understand the underlying specifics of these activities. This is a good thing, because search engines are secretive beasts… er, robots. Robot beasts?

This thesis is based on the following assumptions:
- Googlebot (or any search engine spider) crawls the web to process information. Until Google is able to capture the web through osmosis, this discovery phase will always be essential.
- Google, based on data generated during crawl time discovery, sorts and analyzes URLs in real time to make indexation decisions.
- Based on both of the above activities, a ranking prioritization is generated in real time and constantly fine-tuned.
- The process repeats ad infinitum.
The final step isn’t actually a step so much as a continuum.
Search engines crawl, index, and rank web pages. SEOs should base their tactics on these primary activities. The conclusions for SEOs working at any level boils down to these essential facts:
- It’s all about the crawl
- It’s all about the index
- It’s all about the SERP
But Google (and any search engine) only exists for one reason: to build a business around pleasing its users. Therefore, we must constantly remember:
- It’s really all about the users
And also, because SEO is by nature a competitive exercise, and earning top rankings is at the expense of your competitors, we must note:
- It’s all about the competition
Knowing this, we can initiate several tactics based on each phase of activity, which as an outcome, can help to build an overall SEO strategy. This method ensures we pursue SEO objectives according to the processes search engines currently employ.
The Crawl
SEO begins with the crawl experience of the spider. Googlebot, for example, crawls our site and has a distinct experience, details of which are recorded in full within our server log files. This data can be analyzed in many different ways, including identifying:
- Crawling traps
- Unnecessarily crawled pages
- Duplicate content
- Frequency and depth of crawl
- Existence of 302, 304, 307, 5xx errors and other server response codes
- Existence of redirect chains and loops
- Excessive or unnecessary 404 error pages
Log parsing scripts, such as AudetteMedia’s logfilt, can crunch quickly through loads of data and pull out distinct crawl experience data, ordered in a multitude of ways:

A Yahoo! Slurp crawl analysis from AudetteMedia’s logfilt.
Enterprise-level log analysis tools, such as Splunk, can chunk out details based on user-defined segments such as user-agent sorted by server status code and time/date:

Using Splunk for SEO log file analysis.
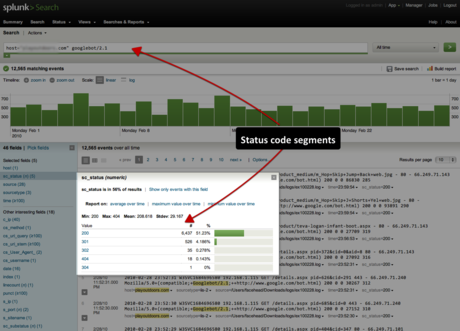
Using Splunk for investigation into Googlebot’s crawl patterns
Xenu is a client-side application that’s capable of modest crawls and provides excellent, actionable data. Xenu will choke on 10,000 pages or more, so is best used as a spot-check tool at the enterprise level. One excellent technique using Xenu, or any quality crawling tool, is to:
- Load the domain or a section of the site into SEMrush
- Export all Google organic URLs into CSV
- Load this file into Xenu or another crawler
- Sort by response code
This quick and simple technique helps to find 302s and other actionable issues.
One of the best tools at the SEO’s disposal is Google’s Webmaster Tools, which can provide insight into crawling issues, duplicate content, and site latency:

Google provides actionable crawl information in Webmaster Tools.
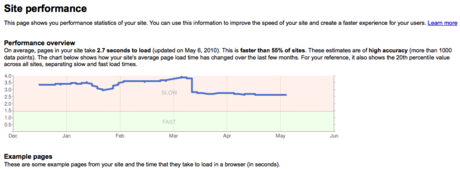
Google’s site performance reporting in Webmaster Tools is helpful, but demanding.
Other useful tools for crawl analysis include Lynx and SEO Browser for viewing pages as a crawler, the ability to fetch as Googlebot in Webmaster Tools, and Charles for deeper SEO diagnostics. Below is an image of Charles during a working session:
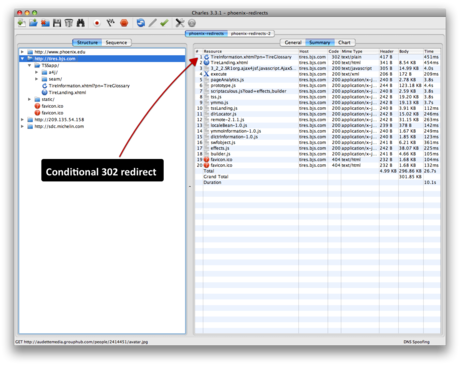
Charles provides excellent information for SEOs.
SEO is About Action
As always with SEO, accurate data is really critical to the process, but overall less important than the actions one takes as outcomes from that data. It’s all about what you do with the information, not what information you can get.
By undergoing a systematic analysis of SEO based on the three primary search engine activities of crawl, index, and rank, savvy SEOs can establish a framework for improving their sites that will reward them with extremely favorable rankings (provided, of course, you deserve to rank in the first place!).
But the real proof is in the pudding. So get out there making pudding (and proving it). And as always, we’ll see you in the SERPs!
Continue reading: “Crawl, Index, Rank, Repeat: A Tactical SEO Framework (Part 2)“, covers indexation, and “Crawl, Index, Rank, Repeat: A Tactical SEO Framework (Part 3)” covers ranking analyses.
Leave a Reply
You must be logged in to post a comment.